Las tablas consisten en una disposición de datos en un arreglo matricial de filas y columnas. Estas tablas pueden mostrar su información de distintas maneras, dependiendo de la información que se quiere mostrar, las unidades de análisis u observación que la componen, la temporalidad de la información que incluyen, el numero de variables que incorporan, etc.
En el uso de R, las arreglos tabulares son ina de las piezas centrales del análisis y manejo de información: es el arreglo de información que conforma a las tibbles y a los data.frames, a partir de los cuales realizamos nuestros análisis, corremos nuestros modelos o hacemos gráficas y visualizaciones.
Dada su importancia en este lenguaje de programación, en el presente texto, vamos a repasar dos de las formas principales en las cuales podemos organizar nuestra información dentro de tablas (formato largo y formato ancho), las ventajas que tienen cada una de esas formas, y finalmente, veremos un ejemplo rápido de la aplicación de las funciones que nos permiten pasar de un tipo de formato al otro.
Formatos ancho y largo.
Dos de los formatos en los que puede presentarse la información dentro de una tabla son el formato largo y el formato ancho.
Ambos formatos son ampliamente utilizados para presentar información y datos abiertos a lo largo del mundo, y, si bien presentan una estructura distinta, ambos son equivalentes y pueden mostrar la misma información.
Formato Ancho
En el formato ancho, los datos para las unidades de observación se presentan a lo largo de columnas diferentes. Esto se muestra en la tabla a continuación:
Tabla formato ancho.
| Persona | Edad | Peso | Altura |
|---|---|---|---|
| Roberto | 32 | 168 | 180 |
| Alicia | 24 | 150 | 175 |
| Esteban | 64 | 144 | 165 |
| Juvenal | 29 | 200 | 185 |
Estas tablas tienen la ventaja de que son muy agradables para la lectura humana.
En este tipo de tablas, incluir nuevos indivíduos hace que la tabla crezca hacia abajo, y incluir nuevas mediciones (fecha de cumpleaños, Índice de masa corporal o Años de educación) hace que la tabla crezca hacia los lados.
Tabla formato largo.
En el formato largo, los datos se presentan a través de dos columnas: una columna (columna de nombres) que nos dice las variables o datos que se estan registrando, mientras que otra columna (columna de valores) registra las magnitudes o valores de dichas variables.
En estas tablas, la unidad de observación es una valor de una medida por persona, en constraste con la anterior, en la cual la unidad de observación es la persona.
| Persona | Variable | Valor |
|---|---|---|
| Roberto | Edad | 32 |
| Roberto | Peso | 168 |
| Roberto | Altura | 180 |
| Alicia | Edad | 24 |
| Alicia | Peso | 150 |
| Alicia | Altura | 175 |
| Esteban | Edad | 64 |
| Esteban | Peso | 144 |
| Esteban | Altura | 165 |
| Juvenal | Edad | 29 |
| Juvenal | Peso | 200 |
| Juvenal | Altura | 185 |
Este tipo de tablas son muy agradables para las máquinas y son muy fáciles de filtrar y graficar en librerías como ggplot2. Se usan principalmente en conjunto con otras funciones del tidyverse para brindar un formato tidy a nuestras tablas y datos.
Los inconvenientes que presentan las tablas en formato “largo” es que dificultan el análisis visual por parte de los lectores de este tipo de tablas y ocupan mayor cantidad de memoria al repetirse valores de identificación de cada una de las observaciones.
A pesar de estas diferencias, hay que tener en cuenta que ambas tablas muestran la misma información, solo que la ordenan de manera diferente.
Funciones tidyr::pivot_longer() y tidyr::pivot_wider().
Las funciones tidyr::pivot_longer() y tidyr::pivot_wider() son las funciones que nos brinda el tidyvderse para poder pasar de una tabla de formato ancho a una tabla de formato largo y viceversa.
Podemos decir que son funciones inversas dentro de R. El resultado de una generalmente puede revertirse usando la función contraria.
La función de pivot_longer() es alargar los datos, incrementando el numero de renglones y disminuyendo el numero de columnas, mientras que la función pivot_wider() tiene como principal función ensanchar los datos, incrementando el número de columnas y disminuyendo el número de renglones.
La documentación oficial de esta función se puede visitar en este enlace
Otros argumentos son:
El argumento
names_to, el cual va a ser el nombre de la columna de nombres. En esta se van a almacenar los nombres de las columnas marcadas en el argumentocols.El argumento
values_to, el cual va a ser la columna que va a almacenar los valores de cada una de las columnas que almacenamos en los nombres.
Un ejemplo de uso, con los datos mostrados arriba, puede verse en la siguiente imagen:
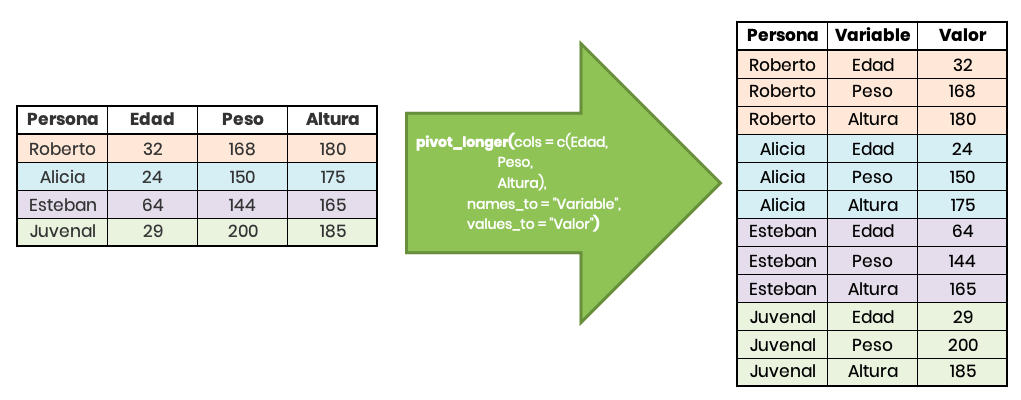
Por su parte, la función tidyr::pivot_wider() requiere de los siguientes argumentos para funcionar:
El argumento
id_cols, el cual va a recibir un vector con las columnas que van a identificar a cada unidad de observación en la tabla de formato ancho.El argumento
names_from, en el cual le pasamos la columna de los nombres que van a conformar las nuevas columnas en la nueva tabla de formato ancho.El argumento
values_from, en el cual le pasamos la columna de los valores que van a ir en las columnas que declaramos en el argumentonames_from.
Un ejemplo de la aplicación de pivot_wider() con las tablas de arriba, puede verse en la siguiente imagen:
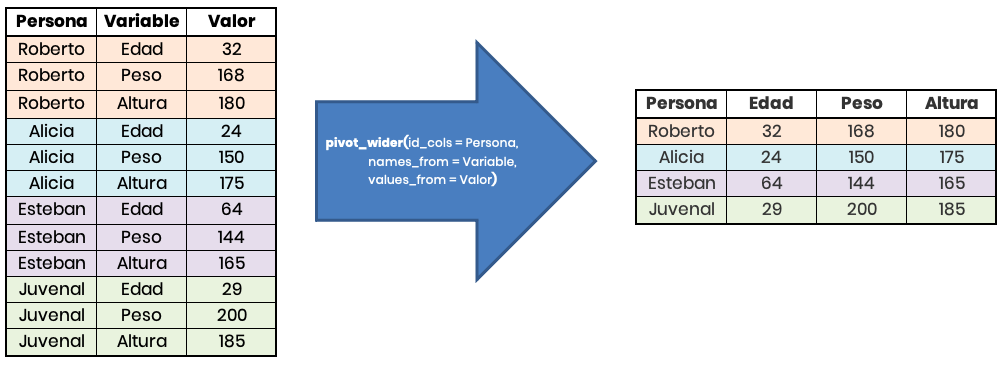
Para practicar, haremos un ejemplo de aplicación de estas funciones en una base de datos reales: La base de datos de casos activos por colonia de la CDMX.
Ejemplo práctico con datos de COVID.
Puedes descargar los datos desde este enlace:
https://archivo.datos.cdmx.gob.mx/sinave-colonias/
Librerías a utilizar.
# Pivotear
library(tidyverse) # Manipular bases de datosbd <- read_csv("https://archivo.datos.cdmx.gob.mx/sinave-colonias/historico_sinave_sep-nov.csv") %>%
select(-X1) # Columna que tiene el numero del renglónEsta tabla esta en formato ancho. En este caso, las unidades de observación (lo que significa cada renglón) son las colonias de la CDMX, mientras que las columnas son el numero de casos activos para cada uno de los días indicados en el nombre de la columna.
Este formato es el formato más agradable para poder realizar mapas: si tuvieramos un archivo *.shp o *.geojson podemos “pegarle” una columna extra con las geometrías de cada colonia (esto lo pueden hacer con las funciones *_join() que revisamos en este tutorial con los datos geográficos de este enlace y la librería sf).
Supongamos que queremos hacer alguna visualización que nos demande una tabla en formato largo. Para transformar la base usaremos la función pivot_longer().
bd_larga <- bd %>%
pivot_longer(cols = contains("total_"),
names_to = "Fechas",
values_to = "casosActivos") Convertimos la variable de Fechas a fechas de verdad. Para esto, elimino la partícula de texto total_ y luego me quedo con las ultimas 2 letras para marcar el día, las letras 3 y 4 para marcar el mes y las letras 1 y 2 para marcar el año.
bd_larga <- bd_larga %>%
mutate(Fechas = str_remove(Fechas, pattern = "total_")) %>%
mutate(Fechas = paste(str_sub(Fechas, start = 5, end = 6),
str_sub(Fechas, start = 3, end = 4),
paste0("20",
str_sub(Fechas,
start = 1,
end = 2)),
sep = "-") %>%
as.Date("%d-%m-%Y"))Ya con este formato podemos hacer gráficas como las gráficas de serie de tiempo, o graficas de barras con facetas, etc. Por ejemplo, para la colonia Roma Sur, podríamos hacer lo siguiente:
bd_larga %>%
filter(colonia == "ROMA SUR I") %>%
ggplot(aes(x = Fechas,
y = casosActivos)) +
geom_point() +
geom_line() +
labs(title = "Casos Activos Colonia Roma Sur I",
subtitle = "Alcaldía Cuauhtemoc, CDMX",
y = "Casos Activos") +
scale_x_date(date_breaks = "1 week")## Warning: Removed 29 rows containing missing values (geom_point).## Warning: Removed 12 row(s) containing missing values (geom_path).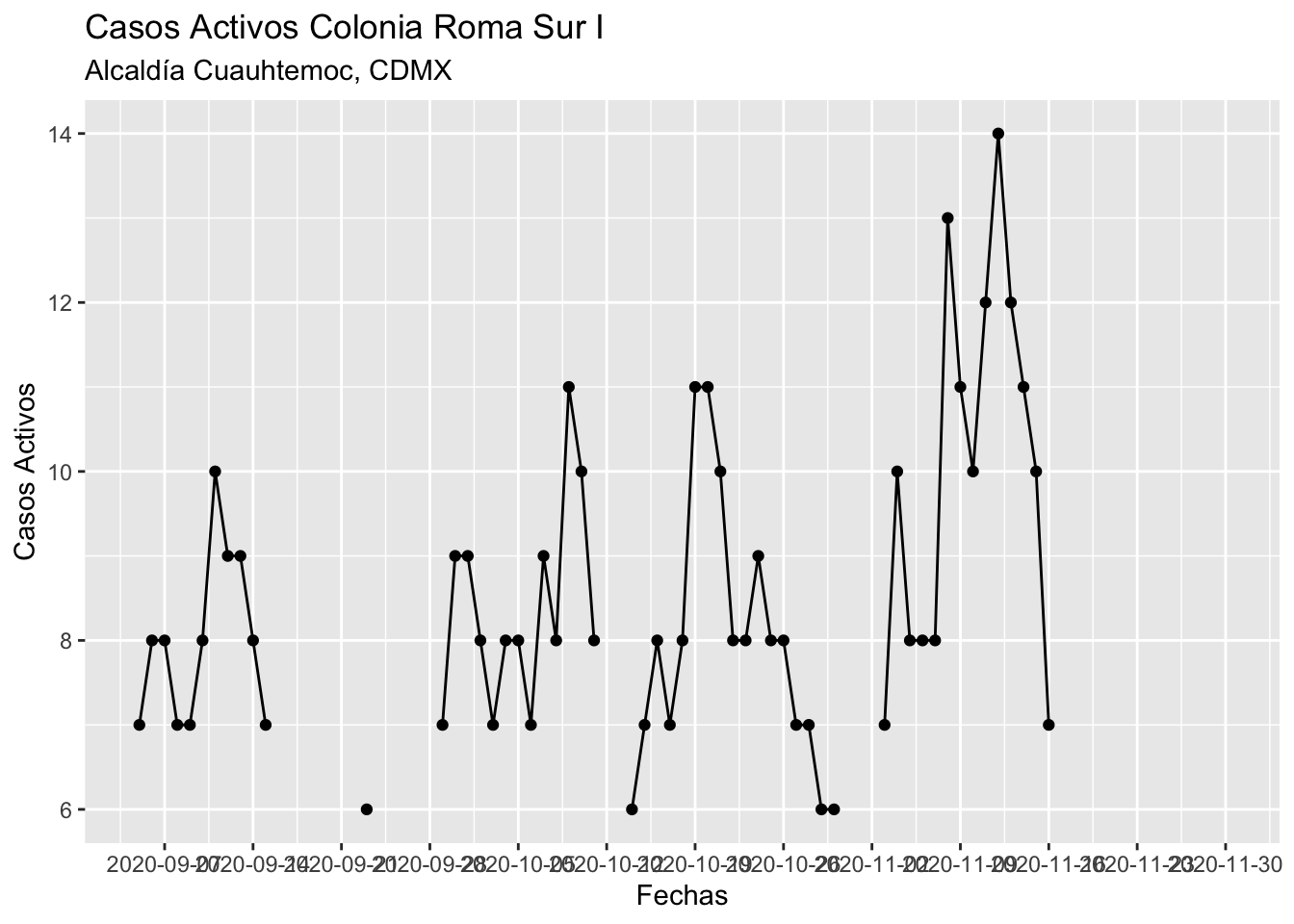
Ahora, para volver al formato largo, podemos hacer lo siguiente:
bd_ancha <- bd_larga %>%
pivot_wider(id_cols = c(alcaldia,
colonia,
clave_colonia),
names_from = Fechas,
values_from = casosActivos,
names_prefix = "valores-")Y de esta manera, la función se encarga de generar las nuevas columnas, de acomodar los datos uno a uno y poner vacíos en caso de que no haya datos para el renglón de la base larga correspondiente.
Conclusiones
Las funciones vistas anteriormente deben formar parte de la caja de herramientas de toda persona que desée trabajar con tablas en R, ya que, tanto para la elaboración de gráficos como para la elaboración de reportes, es necesario hacer cambios de formato para facilitarnos la vida.
Esta explicación y este ejemplo fueron bastante breves y someros, y su objetivo es proveer una breve (pero completa) introducción a los formatos de tabla y a las funciones de pivoteo; sin embargo, es necesario buscar más información y material, y practicar más el uso de estas funciones para poder sacarles todo el jugo y potencial que ofrecen.